
实 验 内 容
自 行 准 备 数 据 集 , 设 计 一 个 数 据 挖 掘 算 法 ( 聚 类 、 分 类 、 频 繁 项 集 挖 掘 或 其 他主 题 ) 对 数 据 集 进 行 信 息 提 取 , 要 求 分 别 使 用 并 行 化 和 非 并 行 化 的 方 式 实 现 该 算法 。
实 验 要 求
自 行 对 比 并 行 化 和 非 并 行 化 实 现 方 法 的 数 据 挖 掘 结 果 , 两 种 结 果 需 完 全 一致 。
有用的参考链接:
我选择实现的是k_means聚类算法。
首先是数据集,我用的是UCI的wine.data,可以点击查看数据集的信息,右键目标另存为直接down下来。

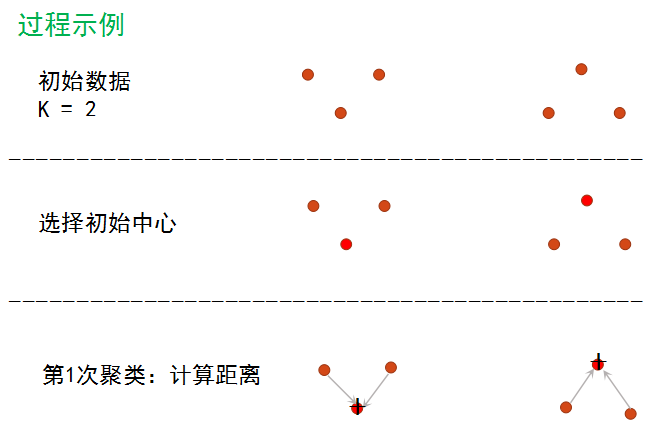
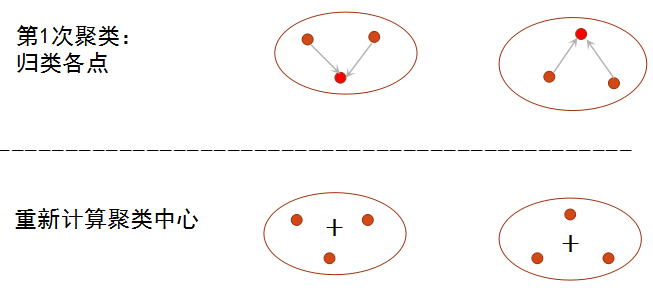
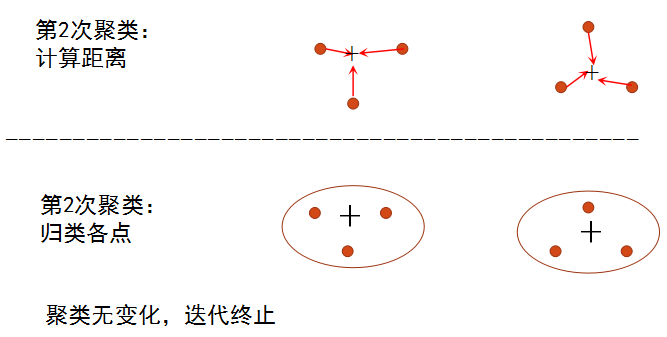
k_means算法的思想:
1)从N个文档随机选取K个文档作为质心
2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类。距离采用标准化欧式距离公式计算。
3)重新计算已经得到的各个类的质心
4)迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束


并行化实现



combiner可以省略,直接reduce。


非并行化实现
思路相同。
数据结构
1 | //中心集合 |
读取wine.data文件
1 | public k_means3(String path) { |
设置K和初始中心点
1 | public void intialCenters() { |
计算过程
1 | public void work() { |
结果:
第一列是所属的类别,第二列往后是各行的数据。
实现后,发现要完全一致,大致看了一下,结果是对的,但是顺序不一样,(ó﹏ò。),不知道为什么MapReduce的输出顺序跟我想的不一样??
非并行化的顺序是按照类别,类别中再按照数据集的顺序。
为了顺序输出,我在map中添加:
1 | ArrayList<ArrayList<Double>> wines = new ArrayList<ArrayList<Double>>(); |
添加cleanup方法
1 | protected void cleanup(Context context) throws IOException, |

嘻嘻嘻٩(๑>◡<๑)۶